


Serverless architecture market size is estimated to be USD 4.25 million in 2018 and is expected to reach USD 14.93 billion by 2023 at a CAGR of 28.6%. – ReportLinker
The ‘serverless’ in serverless computing is more of a misnomer because servers are indeed an integral part of this technology model. Then, the question comes – what is Serverless computing?
Nearly twenty years back, companies used to manage the entire server-side applications. This included – custom engineered programs, management of data servers, configuration of network switches and power requirements of data center racks.
Things got simplified when the concept of cloud computing came in near 2000, and Amazon created its subsidiary Amazon Web Services in August 2006, followed by the launch of Elastic Compute Cloud (EC2). Companies no longer worried about network provisioning, they could simply rent virtual machines and pay for them per usage.
But still, people thought about their systems in terms of servers which they needed to allocate, set up, deploy, monitor and manage. By 2012, people started to look for ways to manage only the operations and not the servers. Applications were to be thought as distributed logic with externally managed data stores. This described serverless computing. It was termed serverless, not because it did not include servers, but because people need not think about them anymore.
So, serverless computing is an evolution of cloud computing models from infrastructure-as-a-service (IaaS) to platform-as-a-service (PaaS) to function-as-a service (FaaS). It is an abstraction of server, infrastructure and the operating system in a way that you don’t need to manage anything, as your cloud provider does that for you.
It can be understood as a car rental service, where you just use the car to reach your destination and pay for the time you sit in the car. You are not concerned with the cost incurred in manufacturing it or managing it.
Growth of Serverless Computing
Per a report by Cloud Foundry, nearly 46% of the companies are using and evaluating serverless computing in 2018 which is a 10% increase from its last survey.

Serverless computing is primarily recognized for its ability to reduce complexity and help companies develop applications faster than ever before.
AWS released the first serverless platform – AWS Lambda in 2014. Other cloud providers like Google and Microsoft also launched their serverless computing services post that.
Serverless offerings like Microsoft Azure functions and AWS Lambda are seeing a strong growth quarter over quarter. No need of managing infrastructure remains the primary reason for this growth.

Since all major cloud providers like AWS, Microsoft, Google and IBM have their serverless offerings in the market, the fight for dominance continues. To be able to decide which one is the leader, we will need to understand each offering and draw a detailed comparison chart.
Serverless Computing Offering Comparison: AWS vs Microsoft vs Google vs IBM
1. AWS serverless offerings: AWS Lambda and AWS Lambda@Edge
a) AWS Lambda
Launch year: November 2014 (preview release), made generally available on April 2016.
What is AWS Lambda?
With AWS Lambda, you can run your code for virtually any kind of application and backend service, without the need of provisioning or managing any servers. You get billed only for the compute time. You will not be charged when your code is not running.
The stateless event-driven compute service by AWS is ideal for applications that don’t require any compute infrastructure provisioning. Thousands of events can run in parallel.
Benefits:
- Run codes with complete automation. There’s no requirement to provision or manage servers.
- Your applications get high scalability as AWS Lambda is capable to run codes in parallel and process each of them individually.
- You are charged for every 100ms your code executes and the number of times a code is triggered. There is no charge when the code is idle.

The above image depicts the flow of process when a code is run on AWS Lambda.
Popular Use Cases:
- It can be used for data processing. A user can trigger Lambda directly by AWS services like S3, Kinesis, DynamoDB, and CloudWatch.
- It can be used for real-time data processing immediately after an upload.
- It can be used for real-time stream processing for application activity tracking, click stream analysis, transaction order processing, metrics generation, data cleansing, IoT device data telemetry etc.
- It can further be used for data validation, sorting, filtering, or other transformations for every data.
- It also finds its usage in backend services like – mobile backends, IoT backends, and web applications.
Pros:
- Reduced cost of execution with sub-second metering.
- There is improved application resiliency as the applications are not hosted on one particular server. If one server goes down, AWS swaps it out automatically, so your code never misses a beat.
Cons:
- Less to no control over environment as they run on industry standard tools through Amazon Machine Instances (AMIs). You will not be able to use any custom packages.
- Complex call patterns as AWS Lambda functions are timeboxed with some default timeout period.
b) Lambda@Edge
Launch date: July 2017
What is AWS Lambda@Edge?
With AWS Lambda@Edge, you can run Lambda functions to modify content that AWS CloudFront delivers. This ensures that the functions are executed at locations closer to the user. These functions always run in response to the CloudFront events, without the requirement of managing servers or provisioning.
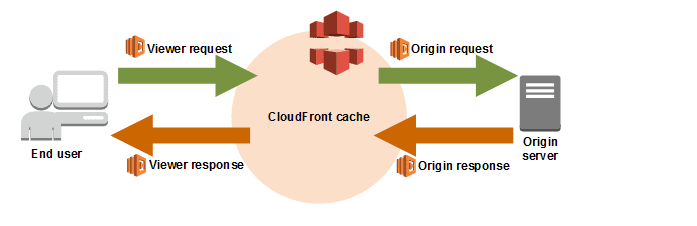
This improves application performance and reduces latency.
Benefits:
- Makes your web applications globally distributed and also improves their performance. Also, as the applications run close to the users, you get to enjoy full-featured and customized content with high-performance.
- No need for server management – automatically scale your code up and down, without the requirement to provision, scale or manage servers.
- Easily customize the content which is delivered through the Amazon CloudFront. Users can also customize their compute resources and execution time.
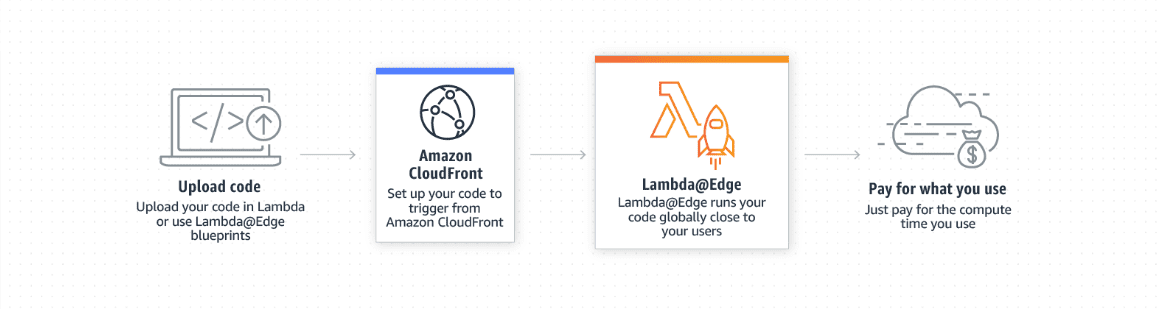
The above image depicts the flow of process in AWS Lambda@Edge when a code is run.
Popular use cases:
- Use Lambda function to add HTTP on origin responses without the need to modify application code at the origin.
- Use Lambda@Edge to simplify and reduce the origin infrastructure.
- Develop dynamic web applications at the Edge with zero origin infrastructure or administration required.
- Improve search engine optimization (SEO) of your website with Lambda@Edge.
- Balance the load on your origin servers, by dynamically routing requests to various origins through Lambda@Edge.
- Block unwanted bots at the edge by smartly mitigating them to protect your origin server from web crawlers.
- It can be used for real-time image transformation.
- It supports A/B testing. So, you can easily compare various versions of your site.
- You can use Lambda@Edge for user authentication, authorization and prioritization.
Pros:
- It’s a step forward by AWS to take the serverless to the edge.
- With it, you can add intelligence to your CDN service without having to worry about the origin server.
Cons:
It is still in the evolving stage as only a limited amount of time has passed since its general availability.
2. Microsoft Serverless offerings – Azure Functions and Azure Event Grid
a) Azure Functions
Launch Date: November 2016
What is Azure Functions?
Azure Functions is the serverless compute offering by Microsoft that enables a user to run code on-demand. The user does not need to explicitly provision or manage infrastructure. With this, the developers can easily run small pieces of code i.e. functions in the cloud. Developers simply need to write the code, without worrying about the underlying infrastructure.
Benefits:
- Simply build apps you need with complete scalability and programming language of your choice, without worrying about infrastructure or servers.
- Use innovative programming model for communicating with other services, orchestrating complex workflows or to build HTTP-based API.
- Leverage built-in continuous deployment and integrated monitoring tools to manage issues.
- Use same function for different targets – Azure Stack, Cloud Service or IoT Edge.

The above image depicts the flow of process in Azure Functions, when a code is run for mobile application backends.
Popular Use Cases:
- For building web application backends.
- For building mobile application backends.
- For real time file processing.
- For real time stream processing.
- For the automation of scheduled tasks.
- For extending SaaS applications.
Pros:
- Functions let you write codes in your chosen language – C#, F#, JavaScript and many other supported languages.
- Simplified Integration lets you easily leverage Azure services and SaaS offerings.
- It is open source and can be found on GitHub too.
Cons:
- The codes are created in the Azure environment and it is difficult to move it to other environments. This creates a vendor lock-in. However, this issue is slowly improving.
b) Azure Event Grid
Launch Date: January 2018
What is Azure Event Grid?
Azure Event Grid serverless offering by Microsoft lets you build web applications with event-based architectures. The users simply need to select the Azure resources they wish to subscribe to, and then choose the WebHook endpoint or event handler they want to send the event to.
Event Grid supports all events coming from Azure services – storage blobs and resource groups. It can support individual events too using custom topics.
Events can be routed to specific events towards different endpoints using filters.
The above image depicts how the event grid connects to various sources and handlers. However, the list is not comprehensive.
Benefits:
- With this, applications and services can easily subscribe to all the required events either from Azure services or from other parts of the same applications.
- As the events are delivered through the push semantics, it simplifies code and reduces the resource consumption.
- Users need to pay based on per event consumption.
Popular Use cases:
- It be used to build reliable cloud applications.
- Build serverless application architectures.
- It can be used to automate operations tools.
- It can be used to integrate your application with other services.
Pros:
- You can build high-volume workloads on Event Grid as it supports millions of events per second.
- The first 100,000 operations per month are free of cost.
Cons:
- It’s still in the developing stage as there’s less time has passed since its launch.
3. Google Serverless Offerings– Cloud Functions and App Engine
a) Cloud Functions
Launch Date: March 2017 (beta release), July 2018 (general availability release level)
What is Google Cloud Functions?
Cloud Functions by Google is a serverless execution environment that can be used to build and connect cloud services. The code is executed in a fully managed environment, without the need of infrastructure or server management.
You can simply write functions that are connected to events associated with your cloud infrastructure or services. The function will be triggered when an event which is being watched is fired.

The above image depicts the flow of process in Cloud Functions when a function is triggered.
Benefits:
- It is the simplest way to run code in the cloud with automatic scaling, fault tolerance and high availability.
- You can simply connect and extend your cloud services with the help of Google Cloud Functions.
- The entire infrastructure and software are fully managed by Google.
Popular Use Cases:
- It can be used to create serverless application backends by simply triggering the code from Google Cloud Platform or calling it directly from any mobile, web or backend application.
- Create real-time data processing systems by running code in response to changes in data.
- Create intelligent applications by easily injecting artificial intelligence into your applications.
Pros:
- Scales automatically depending upon the size of workload.
- It allows you to trigger code from GCP, Google Assistant, Firebase and even call it directly from mobile, web or a backend application.
Cons:
- It supports only Python and JavaScript language for code writing.
b) Google App Engine
Launch Date: Initial Release – April 2017, Stable Release – February 2018
What is Google App Engine?
Google App Engine is Google’s fully managed serverless application platform offering. With it, you can build and deploy your chosen applications on a fully managed platform. Applications can be scaled per requirement, without having to manage or worry about the underlying infrastructure.
It supports various popular languages like Java, Python, PHP, C#, .Net, Go, Ruby or custom languages. As there are zero deployment needs, developers can start quickly with app building. They can further use tools like Cloud SDK, IntelliJ IDEA, Cloud Source Repositories, PowerShell and Visual Studio to manage resources from the command line or run API backends.
Benefits:
- Zero deployment and configuration needs ensure that the developer can solely focus on building great applications.
- App Engine helps the developers to stay productive and agile through various developer tools and support for development languages.
- Developers can focus on adding code without worrying about the underlying infrastructure.
Popular Use Cases:
- For building modern web applications for quickly reaching out to the customers and the end users.

- For building scalable mobile backends
Pros:
- No need to buy or manage any server or server space.
- It is free up to a certain level of consumed resources.
Cons:
- Developers have no control over the environment which sometimes raises the issue of vendor lock-in.
- Developers have access to only read filesystem on App Engine.
4. IBM serverless offering – IBM Cloud Functions based on Apache OpenWhisk
Launch Date: December 2016
What is IBM Cloud Functions?
The IBM Cloud Functions is based on Apache OpenWhisk that provides an ecosystem, wherein developers can write and share code across environments. Developers get to execute their code on demand in a highly scalable environment, without any vendor lock-in issues or server management needs.
IBM Cloud Functions as a function-as-a-service (FaaS) supports many application development languages.
Benefits:
- Offers an open-ended ecosystem where anyone can contribute their code as the building blocks to the growing repository.
- Leverage the capabilities of IBM Watson – cognitive services with access to Watson APIs.
- Pay only for what you use. Cost may increase when more OpenWhisk intensive solutions are constructed.
Popular Use Cases:
- For building serverless web applications and APIs.
- For building serverless backend for a mobile application.
- For creating video search consoles using IBM Cloudant and Watson Visual Recognition services.
- For data processing and identifying changes in data and response to such changes.
- For building microservices.
Pros:
- Easy access to IBM Watson through API helps in bringing cognitive capabilities to serverless.
Quick Comparison Chart
Comparison of serverless offerings by AWS, Microsoft, Google and IBM Cloud
| Features | Amazon Web Services (AWS) | Microsoft | IBM | |
| Serverless Compute Offerings | Lambda Lambda@Edge |
Azure Functions Azure Event Grid |
Google Cloud Functions Google App Engine |
IBM Cloud Functions |
| Maximum Functions | Lambda – Unlimited Lambda@Edge – 25 per AWS account |
Unlimited | 1000 per project | Unlimited |
| Scalability & Availability | Transparent – Automatic Scaling | Automatic scaling | Automatic | Automatic |
| Languages supported |
|
Node.js, C#, Python, F#, PHP, Bash, Batch, executable for Azure Functions |
Node.js | Binaries in Docker, Python, Swift, Node.js, Java |
| Max. execution time | 300 seconds (5 minutes) in Lambda | 300 seconds | 540 seconds | 600 seconds |
| Max Code Size | 50 MB compressed 250 MB uncompressed |
None User pays the storage cost |
100 MB compressed 500 MB uncompressed |
48 MB |
| Monitoring | Dashbird, CloudWatch | Azure Application Insights | Stackdriver | IBM Cloud Shell |
| Concurrent Executions | 1000 concurrent executions per account per region | 10 concurrent executions per function | 400 per function | 1000 per project |
| Triggers |
|
Queues, Schedule, HTTP, Events, Blob Storage | Cloud Storage, HTTP, Cloud Pub/Sub | Periodic Triggers, webhook triggers for GitHub, Cloudant noSQL DB, Push Notification Service, Message Hub Service, Watson, Slack APIs, websocket, weather |
| Web Editing | Web Editing | Provided | Via Google Cloud Source | Provided |
| Logs | Via CloudWatch Logs | Available | Via CLI and Stackdriver | Yes |
| HTTP | Must be triggered through an API gateway | Directly triggered via HTTP | Can be directly triggered via HTTP | Yes |
| Orchestration | Via the step functions | Via Logic Apps | No | Via Rules |
| Version Control | Versioning and aliases | Via GitHub and other similar platforms | Via Google Cloud Source | No |
| Deployments | .ZIP to S3 or Lambda | Via GitHub, Visual Studio, Local git, Dropbox, Bitbucket | Google Cloud Source and .ZIP to cloud storage | GitHub, Bluemix DevOps |
| Access Management | IAM roles (identity and access management) | IAM roles | IAM roles | IAM roles |
| Dependencies | Deployment packages | NuGet, Npm, Visual Studio Team Services | Npm package.json | NA |
| Limits |
Ephemeral disk capacity – 512 MB
|
Azure Functions under consumption plan, limits the execution time to 5 minutes | Function calls per second: 1,000,000 per 100 seconds | Memory – min 256 MB and max 512 MB
Timeout – 60000 ms to 600000 ms |
| Pricing |
|
Azure Event Grid – Price per million operations $0.60 | 2 million invocations free. $0.40/million invocations
$0.0000025/GB-sec with 400,00 GB-sec/month for free $0.0000100/GHz-sec with 200,000 GHz-sec/month for free |
Basic Cloud Function Rate: $0.000017 per second of execution, per GB of memory allocated
API Gateway: Free/No Limits |
Sources:
- https://www.prnewswire.com/news-releases/the-serverless-architecture-market-size-is-estimated-to-be-usd-4-25-billion-in-2018-and-expected-to-reach-usd-14-93-billion-by-2023–at-a-compound-annual-growth-rate-cagr-of-28-6-300699706.html
- https://www.cloudfoundry.org/wp-content/uploads/GPS-7-FINAL-REPORT-.pdf
- http://get.cloudability.com/rs/064-CAC-529/images/state-of-cloud-2018-report.pdf
- https://www2.deloitte.com/content/dam/Deloitte/tr/Documents/technology-media-telecommunications/Serverless%20Computing.pdf

